In 1951 Edward Simpson published a paper discussing the interpretation of contingency tables. He discusses a phenomenon that is still occurring in today’s statistics. It is called after his own name, Simpson’s Paradox.
An Example
Simpson’s Paradox can be explained with a simple example. Suppose we are developing a vaccine to prevent a deadly virus from killing people. After years of research, we have finally found a vaccine that could work. Before it can be distributed across the world, it has to be tested first. To keep this example very simple, suppose that there are 5 men and 5 women in this experiment. One man and four women are treated and four men and one woman are not. Among the treated sample only one man and one woman survive, while in the untreated sample three women survive and no man survives. The results of the experiment can be found in the following table below.
| Male | Female | |||
| Untreated | Treated | Untreated | Treated | |
| Alive | 75% (3/4) | 100% (1/1) | 0% (0/1) | 25% (1/4) |
| Dead | 25% (1/4) | 0% (0/1) | 100% (1/1) | 75% (3/4) |
According to the table, it seems that our vaccine has a positive association between the treatment and survival of both males and females, as the treated subsamples seem to have higher probabilities of survival. However, when we combine the two groups together we get the following.
| Untreated | Treated | |
| Alive | 60% (3/5) | 40% (2/5) |
| Dead | 40% (2/5) | 60% (3/5) |
If we interpret this table, it seems that there is a negative association between treatment and survival in the whole sample. So this would mean that our vaccine does not work accordingly, but which interpretation of the results should we follow?
Definition
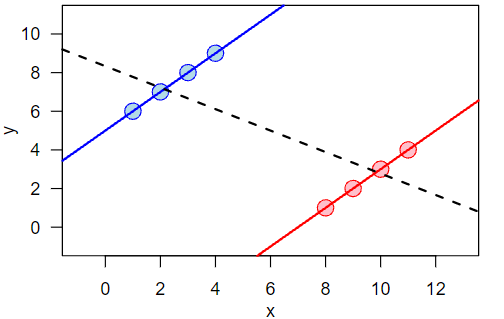
Simpson’s Paradox is a statistical paradox where it is possible to draw two opposite conclusions from the same data depending on how you divide your sample. Graphically speaking, two subgroups will look like to have a positive trend (the blue and red lines) while the whole sample will have a negative trend (the black dotted line), as shown in the figure below.
To give a real-life example, consider the overall 8th-grade standardized test scores in Wisconsin and Texas. The performance of Wisconsin seems to be repeatedly beating the scores of Texas when looking at the overall scores.
| Wisconsin | Texas | |
| 2015 | 159 | 156 |
| 2011 | 159 | 153 |
| 2009 | 157 | 150 |
However, when looking at the sample by ethnicity, which via socioeconomic differences is a major factor in scores, we see something different.
| Wisconsin | Texas | |
| Black | 120 | 137 |
| Hispanic | 138 | 145 |
| White | 166 | 169 |
Clearly, it now seems that Texas schools seem to do a better job than Wisconsin. So the question remains, how do we interpret these kinds of results? Because both conclusions can be drawn from the data, but are completely inconsistent with each other.
Cause
To answer the question that arose from the examples mentioned earlier, it is important to understand how this phenomenon can occur in the first place. Beginning with the first example I mentioned, it showed that a vaccine may not work as well as we thought when looking at the complete sample. However, if we knew more about the characteristics of the participants of the experiment we could give an explanation for the contradictory conclusions. For example, if the treated group consisted of mostly old people that have low survival rates regardless of the treatment, it would make sense that the treated sample seems to be worse off. But this is simply because of the fact that the people in the treated sample are most likely to die anyway. So in order to conduct such an experiment, it is very important to have identical treatment and nontreatment groups.
Furthermore, in our experiment, we did not administer the vaccine evenly around the different subgroups. Only one man got a vaccine and four women. In order to avoid misleading results, it is essential that the vaccine is administered to the same proportion of patients of both sexes. These findings were already established in 1903 with a paper from Udny Yule.
Another great example that explains how Simpson’s Paradox can occur is a paper by Julius von Kugelgen, Luigi Gresele and Bernhard Schölkopf from 2021. They analyse Simpson’s Paradox in COVID-19 case fatality rates. The case fatality rate (CFR) is the rate at which confirmed cases of COVID-19 end fatally. When looking at the CFR data, it seems to be the case that the probability of survival is higher in China than in Italy. This is of course seen from the total population. However, when you break down the data by age group, something interesting happens. It appears to be that in every single age group China has a higher fatality rate than Italy. This is a perfect example of Simpson’s Paradox.
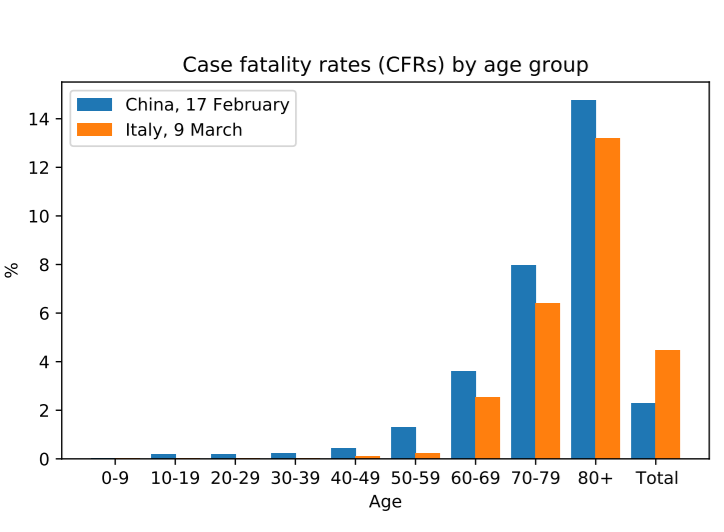
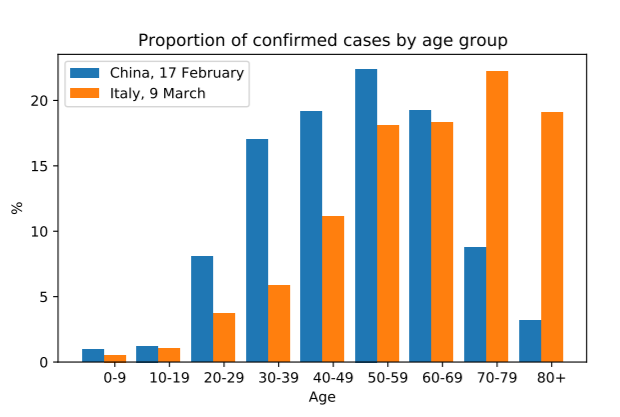
To explain how this can occur we need to look at the age demographics of confirmed cases of each country. When looking at this characteristic it seems to be the case that the population of confirmed cases in Italy are much older than in China. The observed difference could partly be associated with the fact that the Italian population, in general, is older than the Chinese one. However, there are also external factors to be taken into account such as the measures the government takes in both countries to prevent the spread of the disease or even due to the fact that both countries apply different testing strategies. Despite these other factors, the greater share of confirmed cases of older people in Italy, combined with the fact that older people have a lower survival rate when infected, greatly explains the inconsistent conclusions one could take from the data.
Moral of the story
Simpson’s Paradox does not mean that statistics are always going to be paradoxical or confusing. It is more likely that data makes sense when you take a good look at it. Usually, when the right question is asked, it is clear which conclusion can be drawn from the data or a statistic. However, these phenomenons can occur and it is important to understand the context behind a statistic before taking certain conclusions.
References
von Kugelgen, J., Gresele, L., & Scholkopf, B. (2021). Simpson’s Paradox in COVID-19 Case Fatality Rates: A Mediation Analysis of Age-Related Causal Effects. IEEE Transactions on Artificial Intelligence, 2(1), 18–27. https://doi.org/10.1109/tai.2021.3073088
Simpson, E. H. (1951). The Interpretation of Interaction in Contingency Tables. Journal of the Royal Statistical Society: Series B (Methodological), 13(2), 238–241. https://doi.org/10.1111/j.2517-6161.1951.tb00088.x
Yule, G. U. (1903). Notes on the Theory of Association of Attributes in Statistics. Biometrika, 2(2), 121–134. https://doi.org/10.2307/2331677
This article is written by Sam Ansari
